
# scipy를 이용한 독립변수와 종속변수의 관계가 2차 함수인 회귀분석
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df = pd.read_table('income.txt')
for column in df.columns:
num_data = df[column].count() # 해당 열의 비결측값 개수를 반환
print(f"열 '{column}'의 데이터 개수: {num_data}")
df = df.dropna() # 결측값이 포함된 행 제거
# def 함수(y구할때필요한파라미터):
# return y구하는식
# opt, cov = curve_fit(함수, x데이터, y데이터) # opt = 상관계수, cov = 공분산
# ex)
def 함수(x, a, b, c):
return a*x + b*x**2 + c # 2차 함수 가정
opt, cov = curve_fit(함수, df['age'], df['income']) # ex) opt = [a b c]
print(opt)
a, b, c = opt # opt = [a b c]를 변수로 뽑는 방법
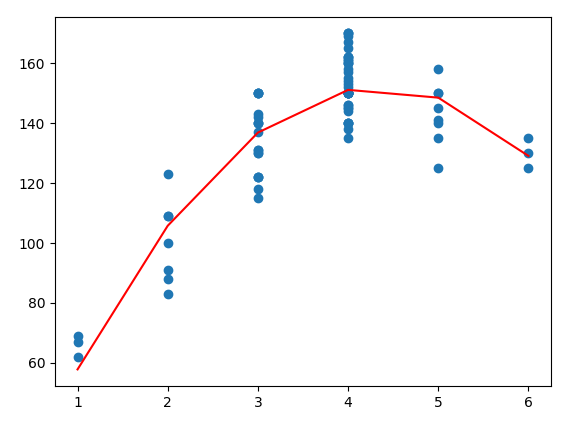
x = np.array([1,2,3,4,5,6]) # np.array로 변환하지 않고 넣으면 오류 발생
plt.scatter( df['age'], df['income'] )
plt.plot(x, 함수(x,a,b,c), color="red")
plt.show()
# Statsmodels를 이용한 독립변수와 종속변수의 관계가 2차 함수인 회귀분석
import statsmodels.api as sm
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_table('income.txt')
for column in df.columns:
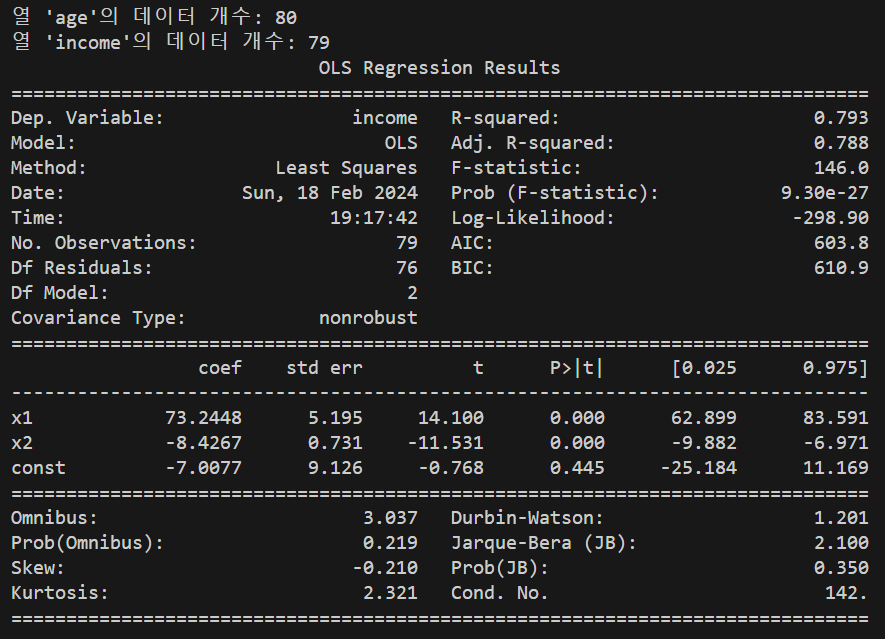
num_data = df[column].count() # 해당 열의 비결측값 개수를 반환
print(f"열 '{column}'의 데이터 개수: {num_data}")
df = df.dropna() # 결측값이 포함된 행 제거
x = np.column_stack([ df['age'], df['age']**2, np.ones(79) ]) # df 행의 개수 79
# np.ones는 모든 데이터가 1이고 사이즈가 78 * 1 벡터, y_i = b0 + b1*x1_i = b2*x2_i 일때 b0 = b0 * 1과 같기 때문
# np.column_stack = 각 벡터의 첫 번째 행 데이터를 추출해서 하나의 리스트로 묶는 작업을 반복하여 2차원 리스트로 만들어줌
# x = [ [첫놈나이, 첫놈나이제곱, 1], [둘째놈나이, 둘째놈나이제곱, 1] ... ]
model = sm.OLS(df['income'], x).fit() # OLS 추정
print(model.summary())
'Python' 카테고리의 다른 글
| 중복 변수 찾고 데이터 추출 (1) | 2024.02.28 |
|---|---|
| IPO stock_crawler (1) | 2024.02.22 |
| Regression_1 (0) | 2024.02.17 |
| 일별종가(시계열 데이터) 시각화 (0) | 2024.02.15 |
| pykrx_상장종목 일별종가 (0) | 2024.02.13 |