
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# -1은 해당 차원의 크기가 다른 차원에 의해 자동으로 조정되도록 함, 열의 수는 1개이고 행의 수는 데이터의 개수에 따라 자동으로 조정되도록 조정
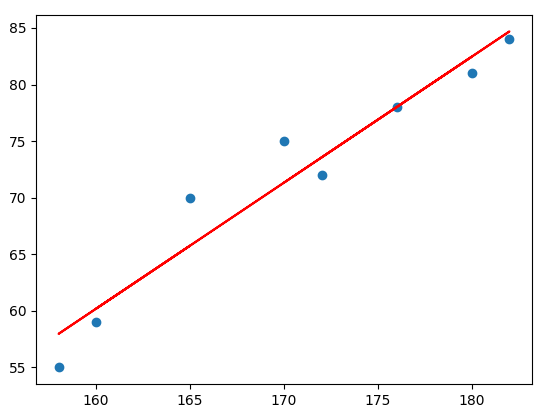
키 = np.array([170,180,160,165,158,176,182,172]).reshape((-1,1))
몸무게 = [75,81,59,70,55,78,84,72]
model = LinearRegression().fit(키, 몸무게)
print(model.score(키, 몸무게)) # R^2 값
print(model.intercept_) # y_i = b0 + b1 * x_i 일때 B0 값
print(model.coef_) # b1 값
plt.scatter(키, 몸무게)
plt.plot(키, model.predict(키), color='red')
plt.show()
-----------------------------------------------------------------------------------------------------------------------------------------------------
# 독립변수가 여러 개인 회귀분석
import numpy as np
import statsmodels.api as sm # regression 결과를 깔끔하게 보여주는 툴
import pandas as pd
df = pd.read_csv('california_housing.csv')
# x1, x2, x3를 [[year1, rooms1, bedrooms1], [year2, rooms2, bedrooms2], ...] 이런 형식으로 넣어야함
# df에서 위 형식으로 x 데이터를 가져오는 방법
# model = sm.OLS(df['price'], df[['year', 'rooms', 'bedrooms']]).fit()
# 상수항을 추가하여 x 데이터 구성
X = sm.add_constant(df[['year', 'rooms', 'bedrooms']])
# OLS 모델 적합
model = sm.OLS(df['price'], X).fit()
print(model.summary())
# 여러 개의 x를 이용한 forecasting을 위해 각 데이터에 상수항을 추가하여 예측
a = model.predict(sm.add_constant([[20, 1000, 200], [10, 500, 100]]))
print(a)

'Python' 카테고리의 다른 글
| IPO stock_crawler (1) | 2024.02.22 |
|---|---|
| Regression_2 (1) | 2024.02.18 |
| 일별종가(시계열 데이터) 시각화 (0) | 2024.02.15 |
| pykrx_상장종목 일별종가 (0) | 2024.02.13 |
| 네이버 파파고 API 활용 (0) | 2024.02.12 |